业余时间自己使用JobSystem 优化了一遍DynamicBone,和大家分享下思路,以此互相交流下是否有更好的优化方案。
这一次的代码不会放出工程源码,因为DynamicBone是需要商店付费的,请大家多多支持原作者。 但是本文会放出Job实现的源码
DyanamicBone主要耗费性能地方
1.UpdateDynamicBones(float t)函数中大量反复计算变量
比如反复计算重力归一化 Vector3 fdir = m_Gravity.normalized;
2.UpdateParticles2函数
反复依赖 Transform, 及 localToWorldMatrix 矩阵变换,浪费性能的矩阵操作 m0.SetColumn(3, p0.m_Position), TransformDirection 等
那么我们开始一步一步优化吧
首先JobSystem 的NativeContainer容器是仅支持struct的,因此第一步开刀的是Particle
修改前
class Particle
{
public Transform m_Transform = null;
public int m_ParentIndex = -1;
public float m_Damping = 0;
public float m_Elasticity = 0;
public float m_Stiffness = 0;
public float m_Inert = 0;
public float m_Friction = 0;
public float m_Radius = 0;
public float m_BoneLength = 0;
public bool m_isCollide = false;
public Vector3 m_Position = Vector3.zero;
public Vector3 m_PrevPosition = Vector3.zero;
public Vector3 m_EndOffset = Vector3.zero;
public Vector3 m_InitLocalPosition = Vector3.zero;
public Quaternion m_InitLocalRotation = Quaternion.identity;
}
修改后,主要是排除Transform的引用, 并使用Unity优化过的数据格式 Unity.Mathematics; 比如float3,float4x4
public struct Particle
{
public int index;
public int m_ParentIndex;
public float m_Damping;
public float m_Elasticity;
public float m_Stiffness;
public float m_Inert;
public float m_Friction;
public float m_Radius;
public float m_BoneLength;
public int m_isCollide;
public float3 m_EndOffset;
public float3 m_InitLocalPosition;
public quaternion m_InitLocalRotation;
}
有的同学此时会问了,排除了Transform组件后,算法中大量的 向量从本地空间转换到世界,或者世界空间转换到本地的计算如何进行?
实际上我们只需要支持 RootBone 节点的世界坐标,再配合Particle自身的localPositon + localRotation 是可以一层一层计算出每个Particle的世界坐标的。
因此我们在Particle加入下列变量.
//for calc worldPos
public float3 localPosition;
public quaternion localRotation;
public float3 tmpWorldPosition;
public float3 tmpPrevWorldPosition;
public float3 parentScale;
public int isRootParticle;
//for output
public float3 worldPosition;
public quaternion worldRotation;
除了Particle 信息外我们还需要知道根骨骼的世界坐标,以及相关全局变量
比如m_ObjectMove,Gravity 等,可以抽象出一个 Struct Head 来存储这些信息
public struct HeadInfo
{
int m_HeadIndex;
public float m_UpdateRate;
public Vector3 m_PerFrameForce;
public Vector3 m_ObjectMove;
public float m_Weight;
public int m_particleCount;
public int m_jobDataOffset;
public float3 m_RootParentBoneWorldPos;
public quaternion m_RootParentBoneWorldRot;
}
准备完基础数据,就要开始JobSystem 化了
考虑的优化方案是
1.完全展开的并行Particle计算
2.完全展开的Transform结算,之所以Transform要完全展开的原因有2点
1)不展开的话,JobSystem无法将Transform分配给多个Worker 来执行,我猜测是由于在层级的中任意一个Transform发生变化,其子节点的Transform也会发生变化,因此符合Woker中并行优化的逻辑(就是只算自己的)
2)可以优化掉Hierachy层级中额外计算量,Unity不会再计算层级嵌套的世界坐标,毕竟你Job里都算了,何必要Unity再算一遍多余计算量
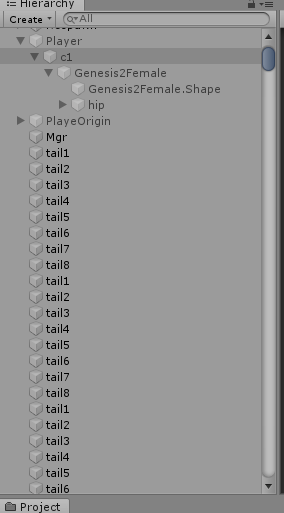
展开后的Transform就像这样
3.最少量的Transform交互,基本每个DynamicBone组只需要一次Transform交互提供根骨骼的世界坐标即可,其他Particle只是跟随根骨骼
4.如果使用GPU蒙皮,那么连展开Transform这一步骤都不需要了
那么具体的Job实现,我拆分为5个步骤
RootPosApplyJob:IJobParallelForTransform 用来一次性输入根骨骼世界坐标
2.PrepareParticleJob:IJob 用来一次性计算所有Particle此时的世界坐标
3.UpdateParticles1Job:IJobParallelFor
4.UpdateParticle2Job:IJobParallelFor
5.ApplyParticleToTransform:IJobParallelFor 结算,将所有结果应用到Transform
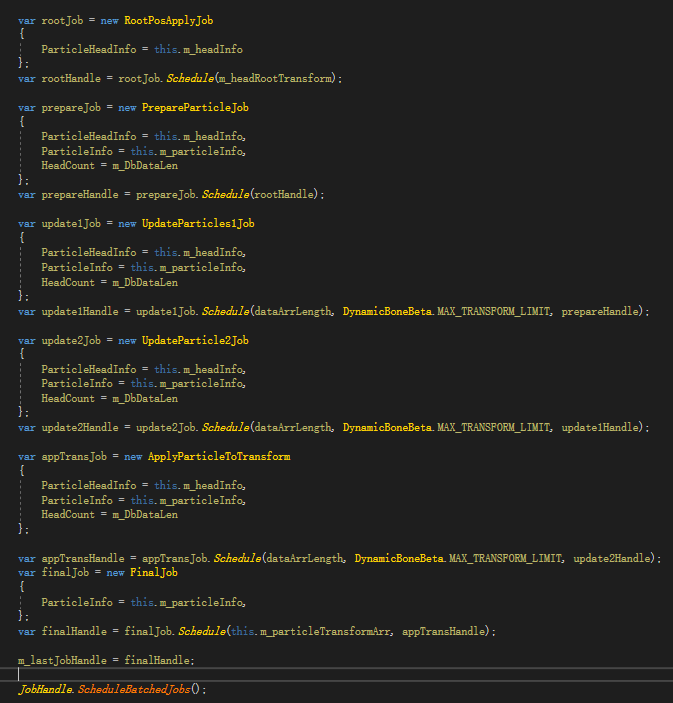
Job依赖执行图
各Job实现
Continue reading