业余时间自己使用JobSystem 优化了一遍DynamicBone,和大家分享下思路,以此互相交流下是否有更好的优化方案。
这一次的代码不会放出工程源码,因为DynamicBone是需要商店付费的,请大家多多支持原作者。 但是本文会放出Job实现的源码
DyanamicBone主要耗费性能地方
1.UpdateDynamicBones(float t)函数中大量反复计算变量
比如反复计算重力归一化 Vector3 fdir = m_Gravity.normalized;
2.UpdateParticles2函数
反复依赖 Transform, 及 localToWorldMatrix 矩阵变换,浪费性能的矩阵操作 m0.SetColumn(3, p0.m_Position), TransformDirection 等
那么我们开始一步一步优化吧
首先JobSystem 的NativeContainer容器是仅支持struct的,因此第一步开刀的是Particle
修改前
class Particle
{
public Transform m_Transform = null;
public int m_ParentIndex = -1;
public float m_Damping = 0;
public float m_Elasticity = 0;
public float m_Stiffness = 0;
public float m_Inert = 0;
public float m_Friction = 0;
public float m_Radius = 0;
public float m_BoneLength = 0;
public bool m_isCollide = false;
public Vector3 m_Position = Vector3.zero;
public Vector3 m_PrevPosition = Vector3.zero;
public Vector3 m_EndOffset = Vector3.zero;
public Vector3 m_InitLocalPosition = Vector3.zero;
public Quaternion m_InitLocalRotation = Quaternion.identity;
}
修改后,主要是排除Transform的引用, 并使用Unity优化过的数据格式 Unity.Mathematics; 比如float3,float4x4
public struct Particle
{
public int index;
public int m_ParentIndex;
public float m_Damping;
public float m_Elasticity;
public float m_Stiffness;
public float m_Inert;
public float m_Friction;
public float m_Radius;
public float m_BoneLength;
public int m_isCollide;
public float3 m_EndOffset;
public float3 m_InitLocalPosition;
public quaternion m_InitLocalRotation;
}
有的同学此时会问了,排除了Transform组件后,算法中大量的 向量从本地空间转换到世界,或者世界空间转换到本地的计算如何进行?
实际上我们只需要支持 RootBone 节点的世界坐标,再配合Particle自身的localPositon + localRotation 是可以一层一层计算出每个Particle的世界坐标的。
因此我们在Particle加入下列变量.
//for calc worldPos
public float3 localPosition;
public quaternion localRotation;
public float3 tmpWorldPosition;
public float3 tmpPrevWorldPosition;
public float3 parentScale;
public int isRootParticle;
//for output
public float3 worldPosition;
public quaternion worldRotation;
除了Particle 信息外我们还需要知道根骨骼的世界坐标,以及相关全局变量
比如m_ObjectMove,Gravity 等,可以抽象出一个 Struct Head 来存储这些信息
public struct HeadInfo
{
int m_HeadIndex;
public float m_UpdateRate;
public Vector3 m_PerFrameForce;
public Vector3 m_ObjectMove;
public float m_Weight;
public int m_particleCount;
public int m_jobDataOffset;
public float3 m_RootParentBoneWorldPos;
public quaternion m_RootParentBoneWorldRot;
}
准备完基础数据,就要开始JobSystem 化了
考虑的优化方案是
1.完全展开的并行Particle计算
2.完全展开的Transform结算,之所以Transform要完全展开的原因有2点
1)不展开的话,JobSystem无法将Transform分配给多个Worker 来执行,我猜测是由于在层级的中任意一个Transform发生变化,其子节点的Transform也会发生变化,因此符合Woker中并行优化的逻辑(就是只算自己的)
2)可以优化掉Hierachy层级中额外计算量,Unity不会再计算层级嵌套的世界坐标,毕竟你Job里都算了,何必要Unity再算一遍多余计算量
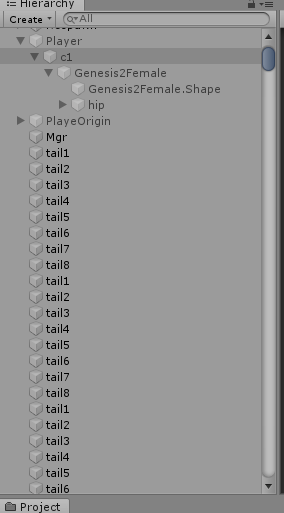
展开后的Transform就像这样
3.最少量的Transform交互,基本每个DynamicBone组只需要一次Transform交互提供根骨骼的世界坐标即可,其他Particle只是跟随根骨骼
4.如果使用GPU蒙皮,那么连展开Transform这一步骤都不需要了
那么具体的Job实现,我拆分为5个步骤
RootPosApplyJob:IJobParallelForTransform 用来一次性输入根骨骼世界坐标
2.PrepareParticleJob:IJob 用来一次性计算所有Particle此时的世界坐标
3.UpdateParticles1Job:IJobParallelFor
4.UpdateParticle2Job:IJobParallelFor
5.ApplyParticleToTransform:IJobParallelFor 结算,将所有结果应用到Transform
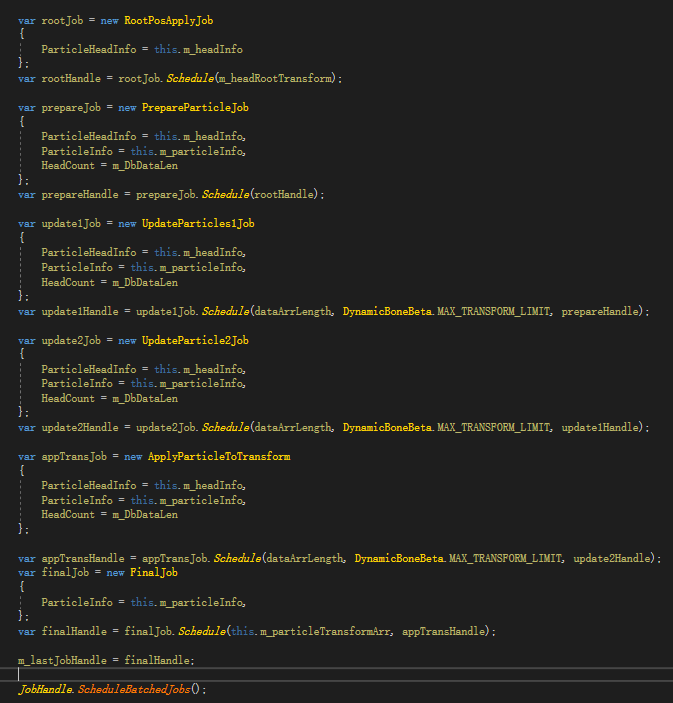
Job依赖执行图
各Job实现
[BurstCompile]
struct RootPosApplyJob : IJobParallelForTransform
{
public NativeArray
public void Execute(int index, TransformAccess transform)
{
DynamicBoneBeta.HeadInfo headInfo = ParticleHeadInfo[index];
headInfo.m_RootParentBoneWorldPos = transform.position;
headInfo.m_RootParentBoneWorldRot = transform.rotation;
ParticleHeadInfo[index] = headInfo;
}
}
[BurstCompile]
struct PrepareParticleJob : IJob
{
[ReadOnly]
public NativeArray
public NativeArray
public int HeadCount;
public void Execute()
{
for (int i = 0; i < HeadCount; i++)
{
DynamicBoneBeta.HeadInfo curHeadInfo = ParticleHeadInfo[i];
float3 parentPosition = curHeadInfo.m_RootParentBoneWorldPos;
quaternion parentRotation = curHeadInfo.m_RootParentBoneWorldRot;
for (int j = 0; j < curHeadInfo.m_particleCount; j++)
{
int pIdx = curHeadInfo.m_jobDataOffset + j;
DynamicBoneBeta.Particle p = ParticleInfo[pIdx];
var localPosition = p.localPosition * p.parentScale;
var localRotation = p.localRotation;
var worldPosition = parentPosition + math.mul(parentRotation, localPosition);
var worldRotation = math.mul(parentRotation, localRotation);
p.worldPosition = worldPosition;
p.worldRotation = worldRotation;
parentPosition = worldPosition;
parentRotation = worldRotation;
ParticleInfo[pIdx] = p;
}
}
}
}
[BurstCompile]
struct UpdateParticles1Job : IJobParallelFor
{
[ReadOnly]
public NativeArray
public NativeArray
public int HeadCount;
public void Execute(int index)
{
{
int headIndex = index / DynamicBoneBeta.MAX_TRANSFORM_LIMIT;
DynamicBoneBeta.HeadInfo curHeadInfo = ParticleHeadInfo[headIndex];
{
int singleId = index % DynamicBoneBeta.MAX_TRANSFORM_LIMIT;
if (singleId >= curHeadInfo.m_particleCount) return;
int pIdx = curHeadInfo.m_jobDataOffset + (index % DynamicBoneBeta.MAX_TRANSFORM_LIMIT);
DynamicBoneBeta.Particle p = ParticleInfo[pIdx];
if (p.m_ParentIndex >= 0)
{
float3 ev = p.tmpWorldPosition - p.tmpPrevWorldPosition;
float3 evrmove = curHeadInfo.m_ObjectMove * p.m_Inert;
p.tmpPrevWorldPosition = p.tmpWorldPosition + evrmove;
float edamping = p.m_Damping;
if (p.m_isCollide == 1)
{
edamping += p.m_Friction;
if (edamping > 1)
edamping = 1;
p.m_isCollide = 0;
}
float3 eForce = curHeadInfo.m_PerFrameForce;
float3 tmp = ev * (1 - edamping) + eForce + evrmove;
p.tmpWorldPosition += tmp;
}
else
{
p.tmpPrevWorldPosition = p.tmpWorldPosition;
p.tmpWorldPosition = p.worldPosition;
}
ParticleInfo[pIdx] = p;
}
}
}
}
[BurstCompile]
struct ApplyParticleToTransform : IJobParallelFor
{
[ReadOnly]
public NativeArray
public NativeArray
public int HeadCount;
public void Execute(int index)
{
{
if (index % DynamicBoneBeta.MAX_TRANSFORM_LIMIT == 0)
{
return;
}
int headIndex = index / DynamicBoneBeta.MAX_TRANSFORM_LIMIT;
DynamicBoneBeta.HeadInfo curHeadInfo = ParticleHeadInfo[headIndex];
{
int singleId = index % DynamicBoneBeta.MAX_TRANSFORM_LIMIT;
if (singleId >= curHeadInfo.m_particleCount) return;
int pIdx = curHeadInfo.m_jobDataOffset + (index % DynamicBoneBeta.MAX_TRANSFORM_LIMIT);
DynamicBoneBeta.Particle p = ParticleInfo[pIdx];
int p0Idx = curHeadInfo.m_jobDataOffset + p.m_ParentIndex;
DynamicBoneBeta.Particle p0 = ParticleInfo[p0Idx];
if (p0.m_ChildCount <= 1)
{
float3 ev = p.localPosition;
float3 ev2 = p.tmpWorldPosition - p0.tmpWorldPosition;
float4x4 epm = float4x4.TRS(p.worldPosition, p.worldRotation, p.parentScale);
var worldV = math.mul(epm, new float4(ev, 0)).xyz;
Quaternion erot = Quaternion.FromToRotation(worldV, ev2);
var eoutputRot = math.mul(erot, p.worldRotation);
p0.worldRotation = eoutputRot;
}
p.worldPosition = p.tmpWorldPosition;
ParticleInfo[pIdx] = p;
ParticleInfo[p0Idx] = p0;
}
}
}
}
[BurstCompile]
struct FinalJob : IJobParallelForTransform
{
[ReadOnly]
public NativeArray
public void Execute(int index, TransformAccess transform)
{
transform.rotation = ParticleInfo[index].worldRotation;
transform.position = ParticleInfo[index].worldPosition;
}
}
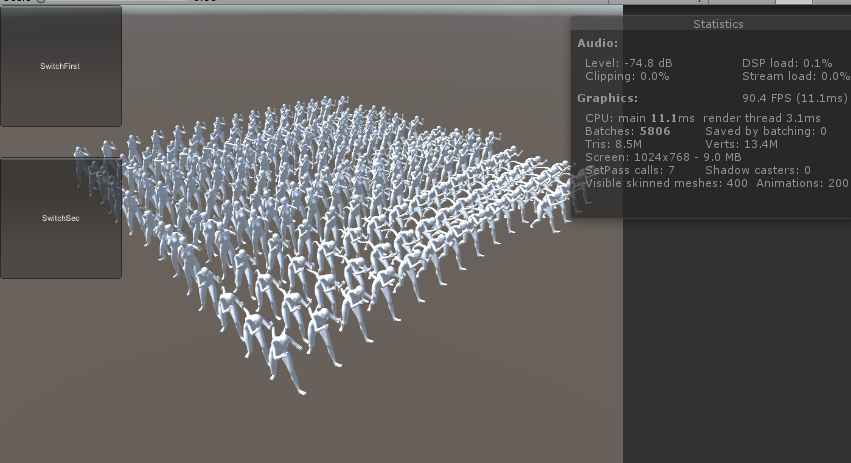
最后是测试效果图
优化后
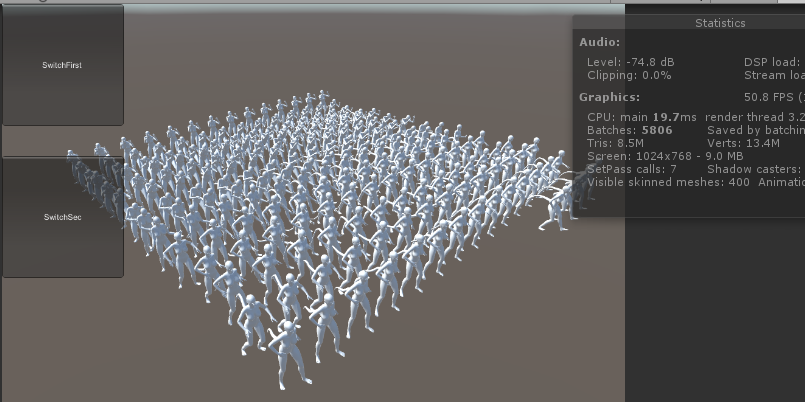
优化前
展开的Transform Job执行分摊情况

这里就不列各种情况数据了,200人的计算性能和空场景的帧数几乎一致90帧。 200人未优化只能到50帧。
最后DynamicBone 其实是可以和蒙皮动画进行整合的
比如 InitTransforms 函数,或者UpdateParticle2中依赖上级节点坐标计算当前差值的地方插入蒙皮骨骼的最终计算值作为初始值即可。 效果就是 模型未运动时表现为蒙皮动画,运动时表现为混合动画。
源码地址
https://github.com/dreamfairy/Unity-DynamicBone-JobSystem-Opmized
òһ
ڼParticleworldPositionʱ
Ϊʲôvar worldPosition = parentPosition + math.mul(parentRotation, localPosition)
ֱvar worldPosition = parentPosition + localPosition
您好,我现在这里遇到了一些困难,我使用了您源码的项目文件,但是在Profiler里面可以看到各Worker在工作,但是Collider这个功能并没有实现,而且DynamicBoneBeta脚本只有依赖DynamicBoneManager才可以生效,否则DynamicBoneBeta脚本挂载到游戏物体上没有任何的作用,这是为什么呢?难道不应该是DynamicBoneBeta版本可以正常运行,然后DynamicBoneManager脚本起到的作用是让把各个方法分别放在Worker中嘛,但是我反复看了您的源码,从DynamicBoneBeta到DynamicBoneManager,真的没有任何的问题,可就不知道为什么将DynamicBoneBeta脚本单独放在游戏物体上的时候,他却不生效呢。希望您可以帮助我解答这个问题,我已经研究了快一个月了,还是没有任何的进展
您好,我现在这里遇到了一些困难,我使用了您源码的项目文件,在Profiler里面可以看到各Worker在工作,1.但是Collider这个功能并没有实现,2.而且DynamicBoneBeta脚本只有依赖DynamicBoneManager才可以生效,DynamicBoneBeta脚本挂载到游戏物体上没有任何的作用,这是为什么呢?我的理解是难道不应该是DynamicBoneBeta版本可以正常运行,然后DynamicBoneManager脚本起到的作用是让把各个方法分别放在Worker中嘛,但是我反复看了您的源码,从DynamicBoneBeta到DynamicBoneManager,真的没有任何的问题,可就不知道为什么将DynamicBoneBeta脚本单独放在游戏物体上的时候,他却不生效呢。希望您可以帮助我解答这个问题,我已经研究了快一个月了,还是没有任何的进展
博主,DynamicBoneCollider这一块好像是没有处理,能提供一下思路吗?
欣睿还在IGG吗?
不在