欢迎使用WordPress。这是您的第一篇文章。编辑或删除它,然后开始写作吧!
Unity 使用 ECS With Burst 来再次加速 GPUSkinning
一般来说使用GpuSkinning 已经能得到很不错的性能了,那么能不能再快一点呢?
答案当然是肯定的,这一次我们来使用ECS榨干CPU的部分
先上性能对比图
1万个蒙皮角色,每个角色472面,带有uv0,uv1
测试设备硬件 win10, Intel i7-7700, GPU GTX-1060 6G
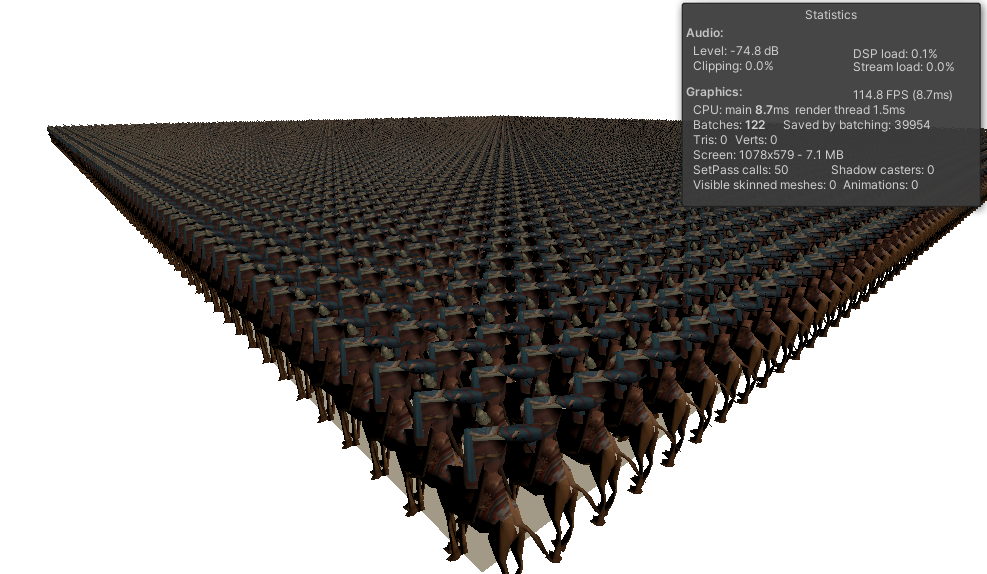
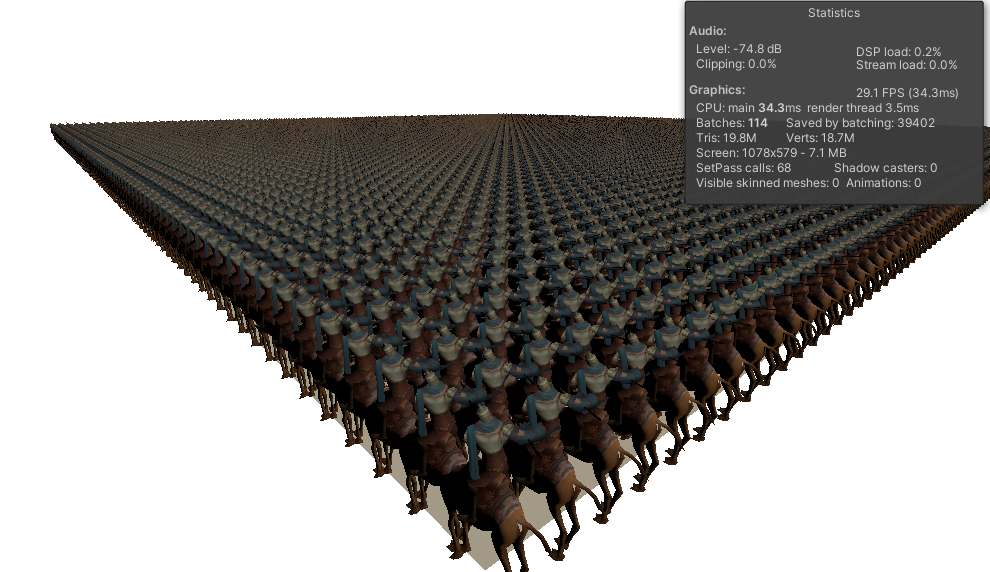
可以看到Entity的帧数在 110帧以上, 而传统GPUSkinning 的帧数在 29帧
这个Demo使用的GPU蒙皮方案为 将骨骼矩阵数据以双四元数的方式存储在纹理上,具体实现方法不是这个Demo的重点,大家也可以参考这篇文章
GPU Skinning 加速骨骼动画
https://github.com/chengkehan/GPUSkinning
接下来一步一步开始分解这个Demo
首先实现Shader Include
Skinning.hlsl
#ifndef __AOI_GPUSKINNING
#define __AOI_GPUSKINNING
TEXTURE2D(_AnimTex);
SAMPLER(sampler_AnimTex);
inline float2 BoneIndexToTexUV(float index, float4 param) {
int row = (int)(index / param.y);
int col = index % param.x;
return float2(col * param.w, row * param.w);
}
inline float3 QuatMulPos(float4 rotation, float3 rhs)
{
float3 qVec = half3(rotation.xyz);
float3 c1 = cross(qVec, rhs);
float3 c2 = cross(qVec, c1);
return rhs + 2 * (c1 * rotation.w + c2);
}
inline float3 QuatMulPos(float4 real, float4 dual, float4 rhs) {
return dual.xyz * rhs.w + QuatMulPos(real, rhs.xyz);
}
inline float4 DQTexSkinning(float4 vertex, float4 texcoord, float4 startData, Texture2D
int index1 = startData.z + texcoord.x;
float4 boneDataReal1 = SAMPLE_TEXTURE2D_LOD(animTex, animTexSample, BoneIndexToTexUV(index1, startData), 0);
float4 boneDataDual1 = SAMPLE_TEXTURE2D_LOD(animTex, animTexSample, BoneIndexToTexUV(index1 + 1, startData), 0);
float4 real1 = boneDataReal1.rgba;
float4 dual1 = boneDataDual1.rgba;
int index2 = startData.z + texcoord.z;
float4 boneDataReal2 = SAMPLE_TEXTURE2D_LOD(animTex, animTexSample, BoneIndexToTexUV(index2, startData), 0);
float4 boneDataDual2 = SAMPLE_TEXTURE2D_LOD(animTex, animTexSample, BoneIndexToTexUV(index2 + 1, startData), 0);
float4 real2 = boneDataReal2.rgba;
float4 dual2 = boneDataDual2.rgba;
float3 position = (dual1.xyz * vertex.w) + QuatMulPos(real1, vertex.xyz);
float4 t0 = float4(position, vertex.w);
position = (dual2.xyz * vertex.w) + QuatMulPos(real2, vertex.xyz);
float4 t1 = float4(position, vertex.w);
return t0 * texcoord.y + t1 * texcoord.w;
}
inline void SkinningTex_float(float4 positionOS, float4 texcoord, float4 frameData, Texture2D
output = float4(DQTexSkinning(positionOS, texcoord, frameData, animTex, animTexSample).xyz,1);
}
#endif
[实战]Unity 基于JobSystem一步一步优化骨骼DynamicBone组件 (源码)
业余时间自己使用JobSystem 优化了一遍DynamicBone,和大家分享下思路,以此互相交流下是否有更好的优化方案。
这一次的代码不会放出工程源码,因为DynamicBone是需要商店付费的,请大家多多支持原作者。 但是本文会放出Job实现的源码
DyanamicBone主要耗费性能地方
1.UpdateDynamicBones(float t)函数中大量反复计算变量
比如反复计算重力归一化 Vector3 fdir = m_Gravity.normalized;
2.UpdateParticles2函数
反复依赖 Transform, 及 localToWorldMatrix 矩阵变换,浪费性能的矩阵操作 m0.SetColumn(3, p0.m_Position), TransformDirection 等
那么我们开始一步一步优化吧
首先JobSystem 的NativeContainer容器是仅支持struct的,因此第一步开刀的是Particle
修改前
class Particle
{
public Transform m_Transform = null;
public int m_ParentIndex = -1;
public float m_Damping = 0;
public float m_Elasticity = 0;
public float m_Stiffness = 0;
public float m_Inert = 0;
public float m_Friction = 0;
public float m_Radius = 0;
public float m_BoneLength = 0;
public bool m_isCollide = false;
public Vector3 m_Position = Vector3.zero;
public Vector3 m_PrevPosition = Vector3.zero;
public Vector3 m_EndOffset = Vector3.zero;
public Vector3 m_InitLocalPosition = Vector3.zero;
public Quaternion m_InitLocalRotation = Quaternion.identity;
}
修改后,主要是排除Transform的引用, 并使用Unity优化过的数据格式 Unity.Mathematics; 比如float3,float4x4
public struct Particle
{
public int index;
public int m_ParentIndex;
public float m_Damping;
public float m_Elasticity;
public float m_Stiffness;
public float m_Inert;
public float m_Friction;
public float m_Radius;
public float m_BoneLength;
public int m_isCollide;
public float3 m_EndOffset;
public float3 m_InitLocalPosition;
public quaternion m_InitLocalRotation;
}
有的同学此时会问了,排除了Transform组件后,算法中大量的 向量从本地空间转换到世界,或者世界空间转换到本地的计算如何进行?
实际上我们只需要支持 RootBone 节点的世界坐标,再配合Particle自身的localPositon + localRotation 是可以一层一层计算出每个Particle的世界坐标的。
因此我们在Particle加入下列变量.
//for calc worldPos
public float3 localPosition;
public quaternion localRotation;
public float3 tmpWorldPosition;
public float3 tmpPrevWorldPosition;
public float3 parentScale;
public int isRootParticle;
//for output
public float3 worldPosition;
public quaternion worldRotation;
除了Particle 信息外我们还需要知道根骨骼的世界坐标,以及相关全局变量
比如m_ObjectMove,Gravity 等,可以抽象出一个 Struct Head 来存储这些信息
public struct HeadInfo
{
int m_HeadIndex;
public float m_UpdateRate;
public Vector3 m_PerFrameForce;
public Vector3 m_ObjectMove;
public float m_Weight;
public int m_particleCount;
public int m_jobDataOffset;
public float3 m_RootParentBoneWorldPos;
public quaternion m_RootParentBoneWorldRot;
}
准备完基础数据,就要开始JobSystem 化了
考虑的优化方案是
1.完全展开的并行Particle计算
2.完全展开的Transform结算,之所以Transform要完全展开的原因有2点
1)不展开的话,JobSystem无法将Transform分配给多个Worker 来执行,我猜测是由于在层级的中任意一个Transform发生变化,其子节点的Transform也会发生变化,因此符合Woker中并行优化的逻辑(就是只算自己的)
2)可以优化掉Hierachy层级中额外计算量,Unity不会再计算层级嵌套的世界坐标,毕竟你Job里都算了,何必要Unity再算一遍多余计算量
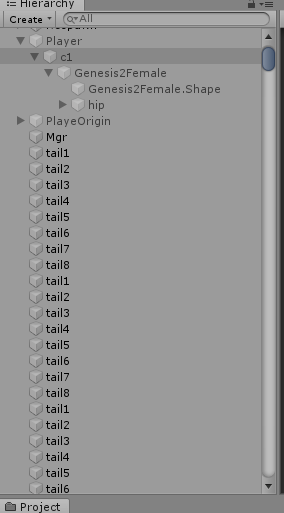
展开后的Transform就像这样
3.最少量的Transform交互,基本每个DynamicBone组只需要一次Transform交互提供根骨骼的世界坐标即可,其他Particle只是跟随根骨骼
4.如果使用GPU蒙皮,那么连展开Transform这一步骤都不需要了
那么具体的Job实现,我拆分为5个步骤
RootPosApplyJob:IJobParallelForTransform 用来一次性输入根骨骼世界坐标
2.PrepareParticleJob:IJob 用来一次性计算所有Particle此时的世界坐标
3.UpdateParticles1Job:IJobParallelFor
4.UpdateParticle2Job:IJobParallelFor
5.ApplyParticleToTransform:IJobParallelFor 结算,将所有结果应用到Transform
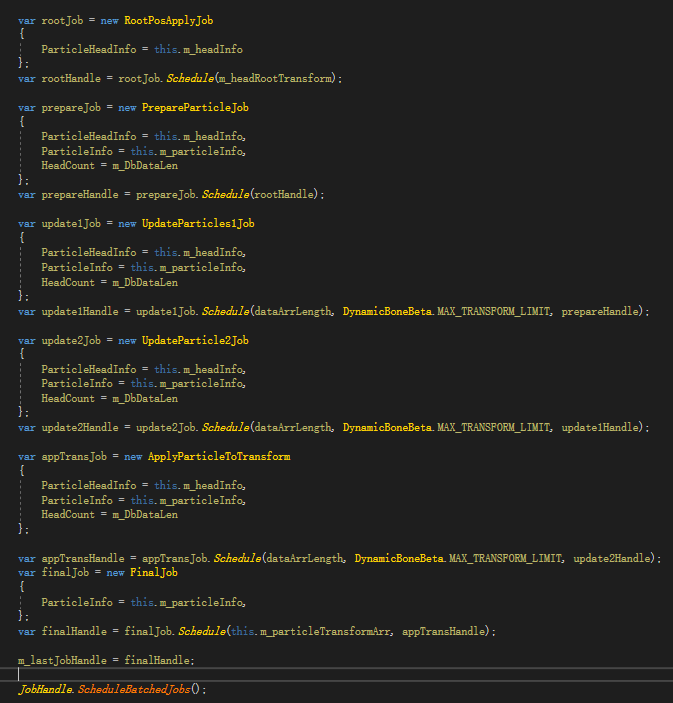
Job依赖执行图
各Job实现
Continue reading
Unity中实现可交互水体
效果图

制作可交互的水体,大致分为三步
1.标记水体碰撞的位置
2.计算水波的传递 通过波动公式,3D或者2D 波动公式都行
3.水面顶点采样波动传递结果计算结果做顶点Y轴偏移
本文参考的波动相关资料
https://en.wikipedia.org/wiki/Wave_equation
https://www.amazon.com/Mathematics-Programming-Computer-Graphics-Third/dp/1435458869 流体 章节
相关公式

根据公式可知波的下次一次传递 z(i,j,k+1) 为 当前波值+上一次波值+周围波值
当前波值 *= (4-8*c^2*t^2/d^2/d^2)/(u*t)
上一次波值 *= (ut-2) / (ut + 2)
四周波值 *= (2c^2t^2/d^2) / (ut + 2)
其中各参数含义为 c 波速, u 粘度, d 波的递进距离, t 为递进时间
ok~ 我们重头开始
首先要建立水面
这里直接用Unity Wiki的轮子的创建平面
https://wiki.unity3d.com/index.php/CreatePlane

这里我们直接创建一个宽10米,长10米,间隔100的平面, 间隔越多,水体的颗粒感越小
对应本文开头描述的三大步骤
创建3个纹理
对应水体碰撞标记,传递,渲染
m_waterWaveMarkTexture = new RenderTexture(WaveTextureResolution, WaveTextureResolution, 0, RenderTextureFormat.Default);
m_waterWaveMarkTexture.name = "m_waterWaveMarkTexture";
m_waveTransmitTexture = new RenderTexture(WaveTextureResolution, WaveTextureResolution, 0, RenderTextureFormat.Default);
m_waveTransmitTexture.name = "m_waveTransmitTexture";
m_prevWaveMarkTexture = new RenderTexture(WaveTextureResolution, WaveTextureResolution, 0, RenderTextureFormat.Default);
m_prevWaveMarkTexture.name = "m_prevWaveMarkTexture";
标记水体碰撞位置
void WaterPlaneCollider()
{
hasHit = false;
if (Input.GetMouseButton(0))
{
Ray ray = Camera.main.ScreenPointToRay(Input.mousePosition);
RaycastHit hitInfo = new RaycastHit();
bool ret = Physics.Raycast(ray.origin, ray.direction, out hitInfo);
if (ret)
{
Vector3 waterPlaneSpacePos = WaterPlane.transform.worldToLocalMatrix * new Vector4(hitInfo.point.x, hitInfo.point.y, hitInfo.point.z, 1);
float dx = (waterPlaneSpacePos.x / WaterPlaneWidth) + 0.5f;
float dy = (waterPlaneSpacePos.z / WaterPlaneLength) + 0.5f;
hitPos.Set(dx, dy);
m_waveMarkParams.Set(dx, dy, WaveRadius * WaveRadius, WaveHeight);
hasHit = true;
}
}
}
由于我们默认Raycast 获取的是碰撞的世界坐标,我们期望的是直接获取到 [0-1] 范围的数值用来映射到uv空间,直接在 m_waterWaveMarkTexture 进行标记, 因此我们乘以一个 world2Local 矩阵变换到本地, 又因为CreatePlane默认创建的Pivot 位于中心,再除以宽高缩放到1区间时,值域落在[-0.5,0.5]上,因此我们还要做 + 0.5偏移
标记水体碰撞Shader
float dx = i.uv.x - _WaveMarkParams.x;
float dy = i.uv.y - _WaveMarkParams.y;
float disSqr = dx * dx + dy * dy;
int hasCol = step(0, _WaveMarkParams.z - disSqr);
float waveValue = DecodeHeight(tex2D(_MainTex, i.uv));
if (hasCol == 1) {
waveValue = _WaveMarkParams.w;
}
根据传入的_WaveMarkParams.xy 跟当前uv 对比,在笔刷范围内的像素标记位默认波高度
波的传递Shader
static const float2 WAVE_DIR[4] = { float2(1, 0), float2(0, 1), float2(-1, 0), float2(0, -1) };
float dx = _WaveTransmitParams.w;
float avgWaveHeight = 0;
for (int s = 0; s < 4; s++)
{
avgWaveHeight += DecodeHeight(tex2D(_MainTex, i.uv + WAVE_DIR[s] * dx));
}
//(2 * c^2 * t^2 / d ^2) / (u * t + 2)*(z(x + dx, y, t) + z(x - dx, y, t) + z(x, y + dy, t) + z(x, y - dy, t);
float agWave = _WaveTransmitParams.z * avgWaveHeight;
// (4 - 8 * c^2 * t^2 / d^2) / (u * t + 2)
float curWave = _WaveTransmitParams.x * DecodeHeight(tex2D(_MainTex, i.uv));
// (u * t - 2) / (u * t + 2) * z(x,y,z, t - dt) 上一次波浪值 t - dt
float prevWave = _WaveTransmitParams.y * DecodeHeight(tex2D(_PrevWaveMarkTex, i.uv));
//波衰减
float waveValue = (curWave + prevWave + agWave) * _WaveAtten;
最后就是水体的呈现,因为需要做顶点纹理采样,因此需要至少ES3.0 硬体
v2f vert (appdata v)
{
v2f o;
float4 localPos = v.vertex;
float4 waveTransmit = tex2Dlod(_WaveResult, float4(v.uv, 0, 0));
float waveHeight = DecodeFloatRGBA(waveTransmit);
localPos.y += waveHeight * _WaveScale;
float3 worldPos = mul(unity_ObjectToWorld, localPos);
float3 worldSpaceNormal = mul(unity_ObjectToWorld, v.normal);
float3 worldSpaceViewDir = UnityWorldSpaceViewDir(worldPos);
o.vertex = mul(UNITY_MATRIX_VP, float4(worldPos, 1));
o.uv = v.uv;
o.worldSpaceReflect = reflect(-worldSpaceViewDir, worldSpaceNormal);
return o;
}
github地址
https://github.com/dreamfairy/interactivity-waterplane
从实际项目升级中关于 Unity SRP 的一些评测
Untiy 推出SRP 已经接近一年了,其中官方宣称 LWRP 在2018年年底时已经处于 production ready 既随时可以做产品了,于是改名为URP, 不过 HDRP 还需要2019.4 的到来才能到达完整版。 不过在我看来 URP 还不能说是 production ready 还处于玩具阶段。而且有时候觉得Unity官方对于技术路线偶尔会出现不明确,左右摇摆的情况。比如Unity 2018 新出的Camera.AddCommandBuffer 来做自定义渲染, 这在 Unity 2019 被废除了,取而代之使用 Render Feature /ScriptableRenderPass 来实现,不过这东西也处于实验阶段。
SRP不做任何修改是否可以直接提高项目性能,答案是可以直接减少CPU给GPU准备阶段的性能大约10%左右。无法直接提升GPU的渲染性能,对于不使用任何光照的项目且处于Opengl ES2.0 这类低端机,基本没有任何GPU性能提升。
以目前使用的SRP 有大量Bug 举两个例子
1. [In order to call GetTransformInfoExpectUpToDate, RendererUpdateManager.UpdateAll must be called first.] 莫名的内置渲染错误,无法自己修改。
官方Issue链接 https://issuetracker.unity3d.com/issues/errors-message-at-editor-play?_ga=2.202176470.695125147.1571176891-1511937231.1511185188
2. 使用渲染指令Blit 后,会导致RenderTarget 无法自动恢复原始RenderTarget,需要手动还原SetRenderTarget,这个在之前的CommandBuffer 里都不曾遇到
在项目中期切换到SRP可以直接优化的地方
1.相机Culling优化
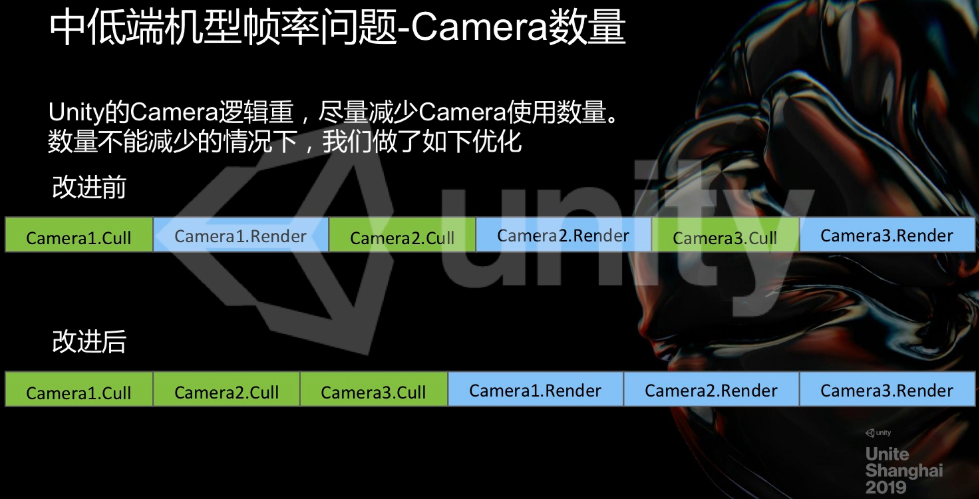
根据官方优化参考,使用SRP后,可以控制相机 Culling(裁剪)行为,对于项目中有自己实现基于投影器Projector的阴影相机可以复用主相机的 Culling结果, 对于UI上模型RT相机可以不做任何Culling
2.相机 Stack 优化
SRP废弃了多个相机的实现,无法再使用多个相机 (比如我们项目1个GamePlay, 1个HUD, 1个UI相机的。使用官方SRP模板,UI相机背景色会盖住场景内容),原因为
如果只使用1个相机,渲染结果可以直接写入BackBuffer
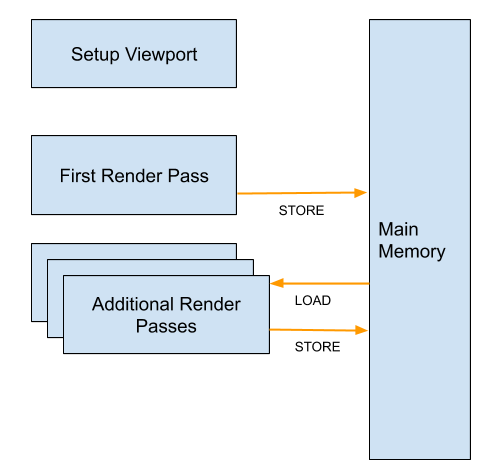
如果有多个相机,由于第二个相机需要第一个相机结果填充画布后再渲染,因此至少需要一张RenderTexture的临时缓冲,且还需要针对不同的Viewport做裁剪等等,写入backBuffer的时机也会延迟
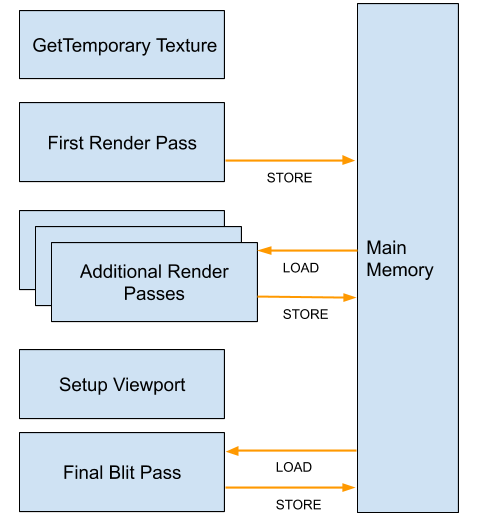
官方文档废弃Camera Stack原因
https://docs.google.com/document/d/1GDePoHGMngJ-S0Da0Fi0Ky8jPxYkQD5AkVFnoxlknUY/edit
3.UI OverDraw 优化
使用同一个相机绘制UI后,可以考虑给UI添加模板测试,将UI挡住场景的部分,场景可以不被绘制到。
4.UI 批次合并(Opengl 3.0+ Unity2019.2+ with SRP Batcher)
对于场景特效类,基本都无缘SRP batcher 他对Cbuffer的容量有限制
对于UI如果全局自定义Shader可以使用 SRP Batcher 不过目前还是实验阶段。
最后来说下 Camera.AddCommandBuffer 这个功能在 Unity 2019 替换为 ScriptableRenderPass 后如何实现一个XRay
使用 CommandBuffer时仅仅需要 camera.AddCommandBuffer(CameraEvent.AfterForwardOpaque, m_XRayBuffer);
然后再XRayBuffer.drawRenderer(renderer, XrayMat)即可
在2019里 需要创建XrayRenderPassFeature 类来实现
public class XRayRenderPassFeature : ScriptableRendererFeature
ScriptableRendererFeature有2个接口要实现分为
Creata() 创建一个实现具体Xray Pass的接口
AddRenderPasses(ScriptableRenderer renderer, ref RenderingData renderingData) 将创角的pass 添加进renderer 队列
在XRayRenderPassFeature 里实现一个 CustomRenderPass : ScriptableRenderPass 来编写具体Xray逻辑
Configure(CommandBuffer cmd, RenderTextureDescriptor cameraTextureDescriptor) 准备阶段
Execute(ScriptableRenderContext context, ref RenderingData renderingData) 渲染阶段
FrameCleanup(CommandBuffer cmd) 清理阶段
基本实现都在Configure里
CommandBuffer xraycmd = CommandBufferPool.Get(m_profilerTag);
xraycmd.DrawMesh(m_drawMesh, m_xrayTarget.transform.localToWorldMatrix, m_xrayMaterial);
context.ExecuteCommandBuffer(xraycmd);
CommandBufferPool.Release(xraycmd);
}
大致流程是,Renderer 会根据 pass 的 renderPassEvent 进行和内置其他pass 比如天空盒,点光,深度 等等其他pass 一起sort, 之后分别在渲染前,渲染,渲染后调用接口
补充一个以官方的SRP FPS Demo 基础来实现XRay
git:https://github.com/Unity-Technologies/UniversalRenderingExamples
1.在FpsSetup 预制体里添加刚刚创建的Feature
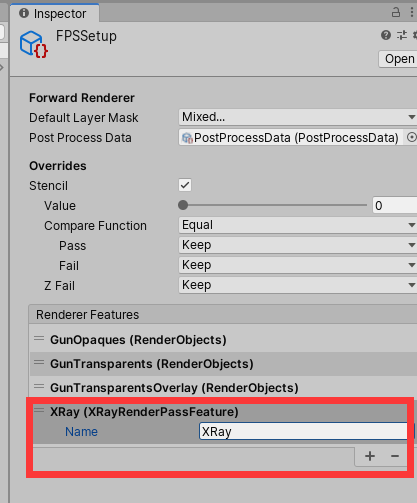
2.编写一个简单ZTest Greater的Shader 用来绘制被遮挡的部分
[cc lang=”C#”]
Shader “Unlit/XrayShader”
{
SubShader
{
Tags { “RenderType”=”Opaque” “LightMode”=”LightweightForward” }
LOD 100
Pass
{
ZTest greater
offset -1,-1
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#include “Packages/com.unity.render-pipelines.universal/ShaderLibrary/core.hlsl”
struct appdata
{
float4 vertex : POSITION;
};
struct v2f
{
float4 vertex : SV_POSITION;
};
v2f vert (appdata v)
{
v2f o;
o.vertex = mul(UNITY_MATRIX_MVP, v.vertex);
return o;
}
float4 frag (v2f i) : SV_Target
{
return float4(1,0,0,1);
}
ENDHLSL
}
}
}
[/cc]
3.在场景中放置一个示例Cube,取名为XRayTarget
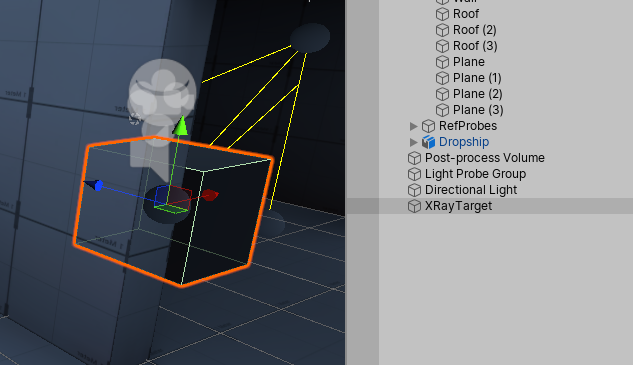
最后运行游戏

最后 使用自定义 ScriptableRendererFeature 的话,还需要自己编写对应的Editor代码,比之前繁琐许多。
如果自己来编写SRP的话,RenderPassFeature 需要自己维护pass列表来实现, 也可以仅仅去实现自定义的ForwardRenderer,可以减少很多功能的重复造轮子。
骨骼动画中的表情制作
好像又快一年没写博客啦 🙁

前一段时时间在做角色表情相关的方案,由于项目中的骨骼计算相关方案都是自己实现的,没有使用Unity SkinnedMeshRenderer, 而且Unity的骨骼方案性能超级烂和各种黑盒代码不能信任,所以表情方案也需要自己来做了。
插个题外话,Unity的骨骼方案到底哪里烂
1.SkinnedMeshRenderer在每帧计算骨骼数据的时候是否有做预计算优化?在抛开动作融合的需求上,实际上所有动画的骨骼计算结果都是可以离线计算的好的,运行时不需要再次从关节骨骼空间变换到模型空间,直接计算好模型空间的数据运行时输出即可。
2.为什么PlayerSetting 里的GPU Skinning选项永远都是*号? 在Opengles3.0以及以下Es2.0 其寄存器数量不会超过256,大部分设备是224个顶点寄存器,假设我在这些设备上上传 1000个骨骼上去,Unity会成功进行GPU Skinning 还是fallback 到Cpu Skinning上?
3.使用Animator制作的大型状态机,如果带有大量动画,那么在加载的时候会加载整个状态机中包含的所有动画,此时加载性能会瞬间达到瓶颈,因此一般MMO项目都会自己来写额外分拆加载逻辑,而且Animator中的State融合时间又很难交给策划灵活配置,最后是很难做网络游戏的表现层和逻辑层分离,似乎是天生对单机游戏亲和力更好。
4.对Instancing的内置没有支持方案,以及没有做JobSystem的整合等等
5.存储空间和计算量大,由于Unity的骨骼使用Matrix4x4 矩阵,实际上骨骼计算使用3×4矩阵就可以满足, 不带缩放的骨骼甚至可以使用 8个float的双四元数就能解决,无论是在叉乘计算还是空间存储极限情况下性能会差距1倍左右
题外话完毕~进入正题啦
业界中制作表情动画的方案大致分2种, 骨骼 或者 BlendShape
什么时候用骨骼? 什么时候用BlendShape?
从要变现的结果上来看,2者都可以实现,但是从制作流程上2者差距很大
骨骼方案
优点:运行时计算量小,离线存储的数据量少
缺点:表情做到一半发现表现不够到位,需要临时增加骨骼,于是又要回炉到3dmax.
针对原画设计的表情,用骨骼细调参数的过程实现需要大量的时间
运行时预设的表情需要策划配置大量不好阅读的参数
BlendShape方案
优点:针对原画设计的表情,美术直接按表情建模即可,效率非常高,对于要做跨人种,高矮胖瘦的体型类变化后的表情支持,可以不受骨骼权重影响,总结就是表现一步到位
缺点:对于三角面较多的模型,做BlendShape的数据量等同于表情数量*模型数量,后期程序可以抽出只发生变化的顶点来存储,但是数据量还是较骨骼来说会多出很多
总结来说,如果不要做挤眉弄眼,只是简单表情的话,直接BlendShape.
如果要做兽人,萝莉,狼人等跨人种 以及变身的话,直接BlendShape.
其他的要做细的表情,可以混合骨骼方案实现
以下是项目中用到的表情资源 BlendShape
1.张嘴

2.闭嘴

3.闭眼

整合后的效果

基于骨骼表情动画资源的话面部会包含较多的骨骼
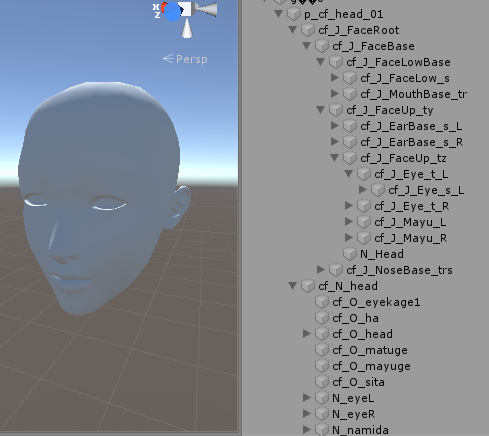
操作骨骼变化表情的效果主要是通过缩放和旋转骨骼来实现

核心代码
[cc lang=”C#”]
void Start()
{
Mf = this.GetComponent
Mr = this.GetComponent
_baseVertices = BaseMesh.vertices;
_baseNormal = BaseMesh.normals;
_tmpVertices = new Vector3[_baseVertices.Length];
_tmpNormal = new Vector3[_baseNormal.Length];
_tmpMesh = new Mesh();
_tmpMesh.vertices = _baseVertices;
_tmpMesh.normals = _baseNormal;
_tmpMesh.triangles = BaseMesh.triangles;
_tmpMesh.uv = BaseMesh.uv;
_tmpMesh.MarkDynamic();
Mf.sharedMesh = _tmpMesh;
_vertexCount = BaseMesh.vertices.Length;
BlendShapeWeight = new float[BlendShapeMesh.Length];
_blendShapes = new BlendShape[BlendShapeMesh.Length];
for (int i = 0; i < BlendShapeMesh.Length; i++)
{
_blendShapes[i] = new BlendShape();
//差异顶点数量
List
for(int j = 0; j < _vertexCount; j++)
{
//变形器与基础顶点的差异
if(_baseVertices[j] != BlendShapeMesh[i].vertices[j])
{
VertexDeltaData blendShapeVertex = new VertexDeltaData();
blendShapeVertex.vertexIdx = j;
blendShapeVertex.deltaVertex = BlendShapeMesh[i].vertices[j] - _baseVertices[j]; //delta position
blendShapeVertex.deltaNormal = BlendShapeMesh[i].normals[j] - _baseNormal[j]; //delta normal
tmpBSVertexList.Add(blendShapeVertex);
}
}
_blendShapes[i].vertices = tmpBSVertexList.ToArray();
}
ModifyWeight();
_hasInited = true;
}
void ModifyWeight()
{
System.Array.Copy(_baseVertices, _tmpVertices, _baseVertices.Length);
System.Array.Copy(_baseNormal, _tmpNormal, _baseNormal.Length);
for(int i = 0; i < BlendShapeMesh.Length; i++)
{
BlendShape curBs = _blendShapes[i];
int deltaDataCount = curBs.vertices.Length;
for(int j = 0; j < deltaDataCount; j++)
{
VertexDeltaData deltaData = curBs.vertices[j];
int idx = deltaData.vertexIdx;
_tmpVertices[idx] += deltaData.deltaVertex * BlendShapeWeight[i];
_tmpNormal[idx] += deltaData.deltaNormal * BlendShapeWeight[i];
}
}
_tmpMesh.vertices = _tmpVertices;
_tmpMesh.normals = _tmpNormal;
}
[/cc]
btw:骨骼动画集大成的学习资料还是要靠隔壁国家的小黄油,推荐下最新的[AI少女]
Unity Projector 投影器原理以及优化
很久很久以前,做过一个离线Mesh切割方式的Decay效果Unity3D中的贴花效果 适合场景景观布置,批次合并等,但运行时性能较差,这次我们来玩玩运行时投影器。
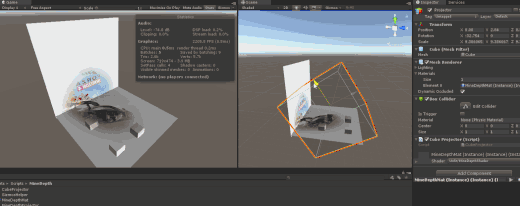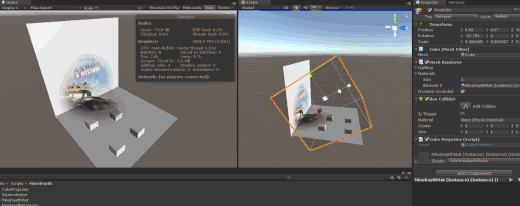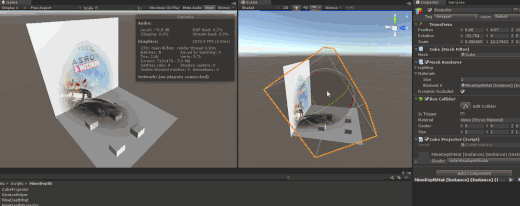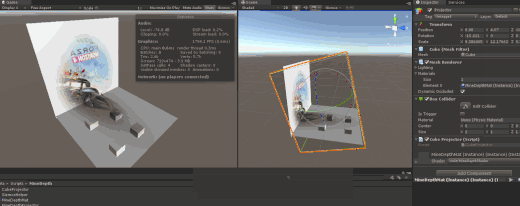
先上成平图

测试效果图, 图中的裤子上投影了一个眼睛
那么投影的原理是什么呢。。。 那么请看下面这张

这张图左下角就是投影器看到的景象,投影贴图“眼睛” 充满了整个投影器的视野,那么原理就呼之而出了。
在正常渲染裤子的顶点时,顺便变换到投影器的屏幕空间,然后再渲染裤子的片段处理函数中将位于投影器屏幕空间的像素都换成眼睛即可。
渲染裤子的Shader
Shader "Unlit/ProjectorShader"
{
Properties
{
_MainTex ("Texture", 2D) = "white" {}
}
SubShader
{
Tags { "RenderType"="Opaque" }
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
};
struct v2f
{
float2 uv : TEXCOORD0;
float4 projectorUV : TEXCOORD1;
float4 vertex : SV_POSITION;
};
float4x4 _ProjectorP;
float4x4 _ProjectorV;
float4x4 _ProjectorVP;
sampler2D _ProjectorTex;
sampler2D _ProjectorFallOut;
sampler2D _MainTex;
float4 _MainTex_ST;
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = TRANSFORM_TEX(v.uv, _MainTex);
float4x4 propMVP = mul(_ProjectorVP, unity_ObjectToWorld);
float4 projProjPos = mul(propMVP, v.vertex);
projProjPos = ComputeScreenPos(projProjPos);
o.projectorUV = projProjPos;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
// sample the texture
fixed4 col = tex2D(_MainTex, i.uv);
fixed4 projectorCol = tex2Dproj(_ProjectorTex, i.projectorUV);
// tex2Dproj = xyz/ w
fixed4 projectorFallOutCol = tex2Dproj(_ProjectorFallOut, i.projectorUV);
projectorCol *= projectorFallOutCol;
col.rgb += projectorCol.rgb;
return col;
}
ENDCG
}
}
}
自定义投影器的CS脚本
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
[ExecuteInEditMode]
public class CustomProjector : MonoBehaviour {
public Camera ProjectorCam;
public Texture2D Tex;
public Texture2D FallOut;
public Material Mat;
private void Start()
{
}
private void Update()
{
Matrix4x4 P = GL.GetGPUProjectionMatrix(ProjectorCam.projectionMatrix, false);
Matrix4x4 V = ProjectorCam.worldToCameraMatrix;
Mat.SetMatrix("_ProjectorV", V);
Mat.SetMatrix("_ProjectorP", P);
Mat.SetMatrix("_ProjectorVP", P * V);
Mat.SetTexture("_ProjectorTex", Tex);
Mat.SetTexture("_ProjectorFallOut", FallOut);
}
}
范例中的代码借用了Unity的相机,实际上并不需要相机,仅仅是借用了相机的投影矩阵和世界空间矩阵而已。
很多项目组在制作移动端游戏时,都使用Projector来制作主角的投影,虽然比起ShadowMap是优化了许多,但是实际上只要和Projector碰撞到物件其DC 都会翻倍, 对于我来说,这还是不可接受的。
而使用上面范例的代码,可以让DC不翻倍,但是并不通用, 因为受Projector影响的物体都需要定制Shader.
Unity自带Projector会翻倍的原因主要也是通用性,跨平台,使用方便, 因此它的原理是
1.找到所有和Projector有碰撞的MeshRenderer
2.使用Projector的材质球,将MeshRenderer的顶点再渲染一遍,并贴图
也因此被投影的物体无法触发动态合批
那么问题来,有没有一种方案,既可以保证通用性,不需要定制被投影目标的Shader,又可以使DC不翻倍呢? 答案是:有的, 但是有代价
代价1:需要使用深度图
代价2:DC不会翻倍,但是总共的DC为,被投影物体数量 + 1. 既物体自带的DC + 1 * (Projector数量) 其实代价2根本不算个事
说搞就搞
1.开启相机的深度渲染
Camera.main.depthTextureMode |= DepthTextureMode.Depth;
2.创建一个表示投影器范围的网格,我搞了个Cube Mesh
3.创建Cube Mesh对应的相关矩阵,因为是Cube 因此创建的投影为正交投影, 当然,如果也可以使用透视投影。
BoxCollider collider = this.GetComponent
this.m_size = collider.size.x / 2;
this.m_nearClip = -collider.size.x / 2;
this.m_farClip = collider.size.x / 2;
this.m_aspect = 1;
Matrix4x4 projector = default(Matrix4x4);
projector = Matrix4x4.Ortho(-m_aspect * m_size, m_aspect * m_size, -m_size, m_size, m_nearClip, m_farClip);
m_worldToProjector = projector * this.transform.worldToLocalMatrix;
MeshRenderer mr = this.GetComponent
mr.sharedMaterial.SetMatrix("_WorldToProjector", m_worldToProjector);
好了,准备工作做完了。开始渲染吧。
首先是将投影器覆盖的区域,采样出当前屏幕空间的深度,类似这样的效果

要实现这样的效果,就是讲顶点变换到投影平面,并将坐标变换到UV值域下
大概这样
vert part
o.screenPos = ComputeScreenPos(o.vertex);
fragment part
fixed4 screenPos = i.screenPos;
screenPos.xy = screenPos.xy / screenPos.w;
float depth = tex2D(_CameraDepthTexture, screenPos).r;
好了,现在我们有了深度,下一部就是讲当前像素的深度还原回该深度对应的世界坐标了
只需要两部矩阵变换
1.从屏幕空间变换到相机空间 unity_CameraInvProjection
2.从相机空间变换到世界空间 unity_MatrixInvV
有了世界坐标后,就可以将该坐标变换到Projector的控件,就是准备工作中的 _WorldToProjector
变换到Projector空间后,还记得范例上的投影器的全部视野就是需要投射的贴图范围吗?因此这里要做UV值域的变换
//变换到自定义投影器投影空间
fixed4 projectorPos = mul(_WorldToProjector, worldSpacePos);
projectorPos /= projectorPos.w;
fixed2 projUV = projectorPos.xy * 0.5 + 0.5; //变换到uv坐标系
fixed4 col = tex2D(_ProjectorTex, projUV); //采样投影贴图
fixed4 mask = tex2D(_ProjectorTexMask, projUV); //采样遮罩贴图
col.rgb = lerp(fixed3(1, 1, 1), col.rgb, (1 - mask.r)); //融合
大功告成! 你可能会好奇,为什么多了一个遮罩贴图? 虽然你讲投影器视野内的像素部分都贴了投影贴图,但是是野外的像素怎么办?这个时候就需要遮罩图抹掉,因此遮罩图的纹理设置要设置为Clamp,保证边缘像素为拉伸且外侧的Alpha为0
Unity3D Entitas ECS 框架
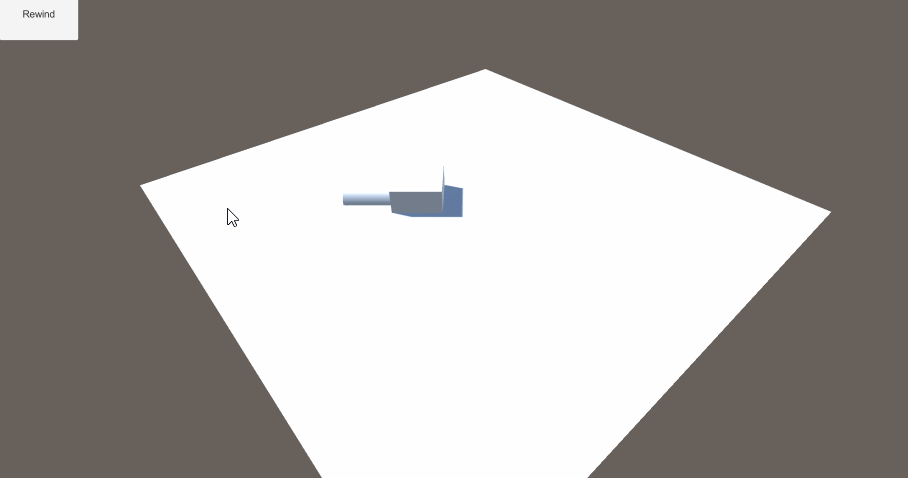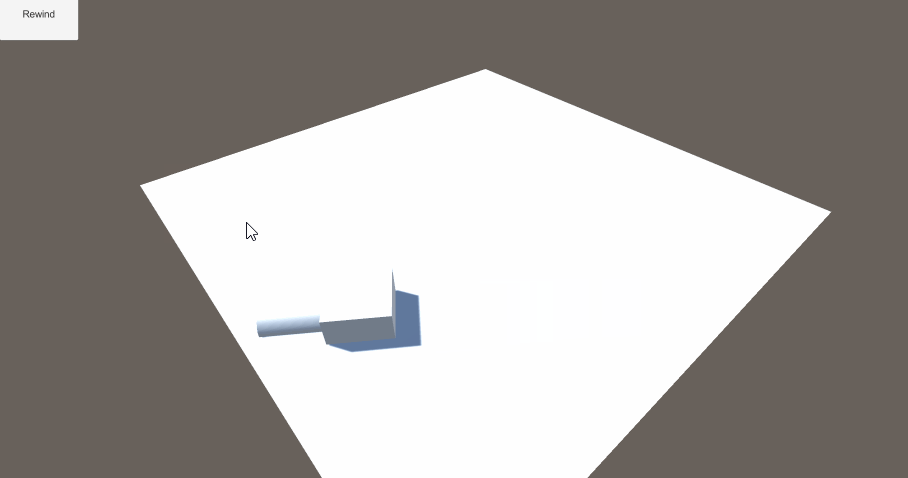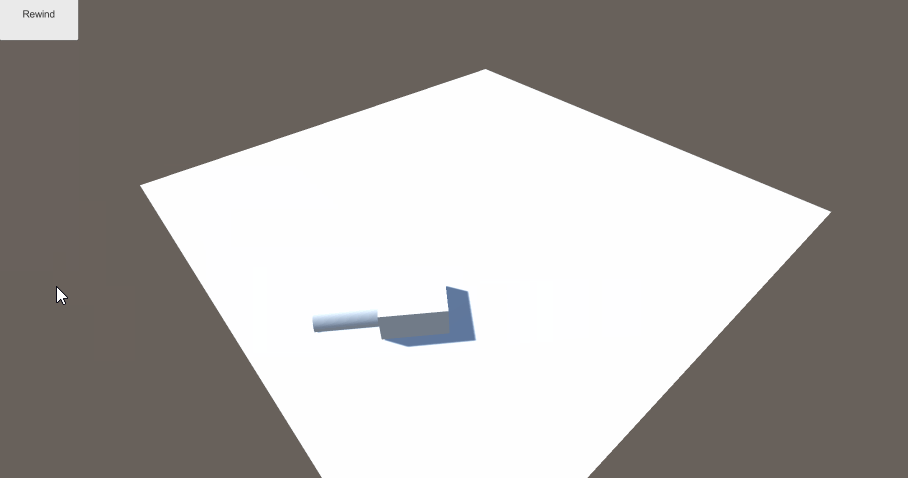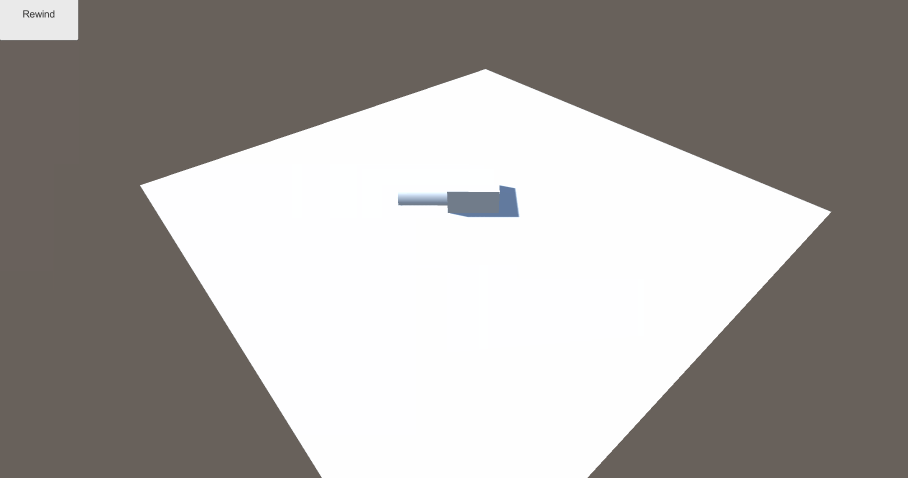
一个使用ECS框架,制定Agent移动, 最后使用倒播功能还原路径的功能演示。
20180502 Unity 2018.1 正式版出来了, 带来了内置的ECS和Job System。 在UnityECS中, Entity对应的是GameObject, Component对应的是MonoBehavior, 而System对应的是ComponentSystem。
不过在写这篇文章的测试demo时使用的还是GitHub上的版本, 两者之间仅有API的名称上的区别。
GitHub地址:https://github.com/sschmid/Entitas-CSharp
安装:
版本 1.52
https://github.com/sschmid/Entitas-CSharp/releases
1.使用已编译的版本 https://github.com/sschmid/Entitas-CSharp/releases/download/1.5.2/Entitas.zip
直接将文件解压到Assets目录下即可
2.使用源码安装 git clone https://github.com/sschmid/Entitas-CSharp.git
1.将Libraries/Dependencies 里的文件全部拷贝到 Plugins 目录下
2.将Entitas 和 Addones 目录拷贝到Assets 目录下
3.随便打开一个C#文件,让Unity生成项目文件后,就可以在工具栏启动 Tools/Entitas/Perfererces
4.如果在第三步出错了,那是因为源码文件中 EntitasResources.cs 取资源目录里的文件Version.txt 失败了, 这是由于Unity生成的dll文件不会包含资源,因此要么修改这个函数直接返回版本号(不取Version),要么直接使用官方已经编译好的Entitas.dll
ECS架构概述
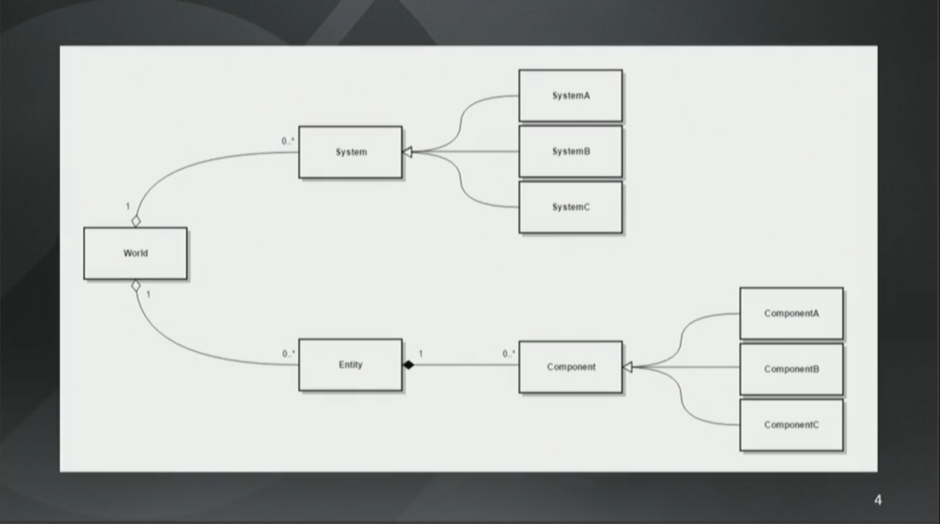
ECS架构看起来就是这样子的。先有个World,它是系统(译注,这里的系统指的是ECS中的S,不是一般意义上的系统,为了方便阅读,下文统称System)和实体(Entity)的集合。而实体就是一个ID,这个ID对应了组件(Component)的集合。组件用来存储游戏状态并且没有任何的行为(Behavior)。System有行为但是没有状态。
这听起来可能挺让人惊讶的,因为组件没有函数而System没有任何字段。
from:http://gad.qq.com/article/detail/28682
ECS框架其实在许多年前就已经诞生了,这几年名声大噪源于GDC2017守望先锋的一次技术分享,ECS的理念是组合模式优于面向对象模式,ECS解决的问题是之前OOP框架开发时状态和行为混合,在对象功能非常庞大时维护的成本很高。
ECS的全称是 Entity , Component, System. 其中Entity是对象实体, Component维护了对象的所有状态, 而System则是利用对象身上的Compoent实现各种行为, 在实际编程发现这种编程方式非常类似行为树的构架,开发过行为树逻辑的同学非常熟悉开发模式就是讲各种逻辑进行拆分,分散一个个处理细节的函数,使这些函数可以被行为树任意组合复用。
C#版的ECS利用了许多C#的特性,比如分散类 partical. ECS中Component 实际上是把OOP中的成员属性变成一个个单独的partical class进行拆分,但是本质上组合后还是属于他的成员。
举个例子, 在OOP中一个玩家包含了生命和移动速度的属性 Like this
[cc]
public class Player {
public uint HP;
public uint MoveSpeed;
}
[/cc]
而在ECS构架中这个类会变成这样
[cc lang=”C#”]
HPComponent.cs
public partial class Player{
public HPComponent hpComponent;
}
MoveSpeedComponent.cs
public partial class Player{
public MoveSpeedComponent moveSpeedComponent
}
[/cc]
这里我为什么要把类名标识出来, 这是因为对于程序员开发来说,当你要修改Player的某个属性时,只要关注属性类即可, 不需要去Player.cs中大海捞针找属性在哪,这是一种开发上的快捷。 而对于编辑器来说,这些类都都是partial 聚合类, 本质上都是Player.cs 的一部分与OOP无差。
XLua 与 ILRuntime 性能测试
首先。。今天是个好日子,因为可以

好了,进入正题
现在很多项目都使用xlua来开发整个项目,但是实际上使用的并不是xlua标榜的“热修复”,毕竟国内游戏还是要要求可以热更新新功能的,因此如果采用热修复的方案,则需要小版本使用lua写功能,大版本又要把lua版本转换为C#代码重写一次,不太现实,因此现实中的许多公司都是使用lua来写大部分的逻辑。
但是u3d是个C#语言为编程语言的引擎(当然还有JS…),一般lua项目中,我们会把逻辑运算量大,复杂度高,对性能有要求的代码写在C#代码,或者C++ DLL库中,比如加载,更新,框架,战斗等, 这就需要程序要经常同时使用C#和lua写代码,容易人格分裂。
在Ilruntime 1.3版本之后,有稳定的调试插件(通过tcp 连接,因此可以真机调试),值绑定等功能后 也成为一个不错选择,程序员不需要更换语言来编写项目。至于它的局限性,对比lua来说都是半斤八两,比如主工程的泛型类无法导出,常用值类型需要生成wrap等(否则会有严重性能问题)。
目前很多人对Ilruntime 的看法有2点。 1,使用的项目比较少,未预见的坑比较多。 2,性能比较差,毕竟lua 有Jit, 在支持Jit的设备上是接近c的性能,大部分的性能损耗在接口交互上,而Ilruntime 是自己实现了一套解释器,是C#编写的,原生性能较差。 因此我打算做一个性能测试,看看真实的情况是什么。
使用的ILruntime库地址
https://github.com/Ourpalm/ILRuntime
使用的Xlua库地址
https://github.com/Tencent/xLua
注:Ilruntime 已经设置全局宏 DISABLE_ILRUNTIME_DEBUG, 并且hotfix项目为Release, 生成了Vecto3_Binding
Xlua 生成了 Vector3_Wrap
.Net 3.5版本下
测试3种情况下的性能情况
Test1 测试U3d内部值计算
ILRuntime:
[cc lang=”C#”]
public void Test1()
{
Stopwatch sw = new Stopwatch();
sw.Start();
for(int i = 0; i < 1000000; i++)
{
Vector3 a = new Vector3(1, 2, 3);
Vector3 b = new Vector3(4, 5, 6);
Vector3 c = a + b;
}
sw.Stop();
UnityEngine.Debug.Log("il test1:" + sw.ElapsedMilliseconds);
}
[/cc]
Xlua:
[cc lang="lua"]
void LuaTest1()
{
System.Diagnostics.Stopwatch sw = new System.Diagnostics.Stopwatch();
sw.Start();
env.DoString(@"
for i = 0, 1000000, 1 do
local a = CS.UnityEngine.Vector3(1,2,3)
local b = CS.UnityEngine.Vector3(4,5,6)
local c = a + b
end
");
sw.Stop();
Debug.Log("lua test1:" + sw.ElapsedMilliseconds);
}
[/cc]
Continue reading
使用xlua 进行Unity3D 热更新-2
一接触到新的东西,总想看看背后的原理是怎样的,xlua也不例外。于是试着写了一下,算是了解底层的实现原理,以后不用xlua也能有借鉴的地方。
xlua的热修复原理实际上是在 C# 编译成中间语言的时候,进行代码的插入这部分用到了 Mono.Ceil 库来操作,当然还有其他很多的库也可以实现。 因为是在IL的部分插入,因此直接支持IL2CPP
直接进入主题
已知有一个类
[cc lang=”C++”]
public class InputTest{
void Start(){
Hello();
}
private void Hello(){
Debug.Log(“hello”);
Debug.Log(“666”):
}
}
[/cc]
这个类在被Unity调用的时候会输出 “Hello”
那么如果我们想修改Hello函数该怎么做呢
[cc lang=”C++”]
string injectPath = @”./Library\ScriptAssemblies\Assembly-CSharp.dll”;
AssemblyDefinition assemblyDefinition = null;
var readerParameters = new ReaderParameters { ReadSymbols = true };
assemblyDefinition = AssemblyDefinition.ReadAssembly(injectPath, readerParameters);
[/cc]
第一步 是要将当前代码的 Assembly 读出来, U3d有3个Assembly。 一个是项目代码叫 Assembly-CSharp.dll 一个是编辑器代码 Assembly-Editor-CSharp.dll.
还有一个是插件 Assembly-Plugin-CSharp.dll. 因为 InputTest是项目代码部分,所以读取 Assembly-CSharp.dll即可
读取成功后,所有的数据都在 assemblyDefinition 中,只需要遍历一下找到要修改的类即可
[cc lang=”C++”]
foreach (Mono.Cecil.TypeDefinition item in assemblyDefinition.MainModule.Types) {
if(item.FullName == “InputTest”) {
foreach (MethodDefinition method in item.Methods) {
if (method.Name.Equals(“Hello”)) {
}
}
}
}
[/cc]
第二步 通过遍历类型定义找到我们的类 “InputTest” 然后在 类定义中遍历所有的函数定义,找到我们要修改的 “Hello”函数
找到函数后,就可以正式做函数修改了。
[cc lang=”C++”]
var ins = method.Body.Instructions.First();
var worker = method.Body.GetILProcessor();
var logRef = assemblyDefinition.MainModule.Import(typeof(Debug).GetMethod(“Log”, new Type[] { typeof(string) }));
worker.InsertBefore(ins, worker.Create(OpCodes.Ldstr, “Fuck Off”));
worker.InsertBefore(ins, worker.Create(OpCodes.Call, logRef));
worker.InsertBefore(ins, worker.Create(OpCodes.Ldstr, “Fuck On”));
worker.InsertBefore(ins, worker.Create(OpCodes.Call, logRef));
Type type = typeof(InjectTest);
if (null != type) {
MethodInfo subMethod = type.GetMethod(“SayFuck”);
if (null != subMethod) {
Debug.Log(“Find Method: ” + subMethod);
var sayRef = assemblyDefinition.MainModule.Import(subMethod);
worker.InsertBefore(ins, worker.Create(OpCodes.Call, sayRef));
}
}
var writerParameters = new WriterParameters { WriteSymbols = true };
assemblyDefinition.Write(injectPath, new WriterParameters());
[/cc]
第三步 做了3件事情, 绑定了2个UnityEngine的Log函数,打印了 “Fuck Off”, “Fuck On” 之后再绑定一个类 “InjectTest”中的静态函数 SayFuck()
这样原本的 Hello()函数就会在 打印”Hello”之前先打印 “Fuck Off”, “Fuck On” 调用 InjectTest.SayFuck().
最后就是将执行的修改进行保存 assemblyDefinition.Write
最后的最后用C#反编译软件打开 Assembly-CSharp.dll 看看修改后的Hello()函数
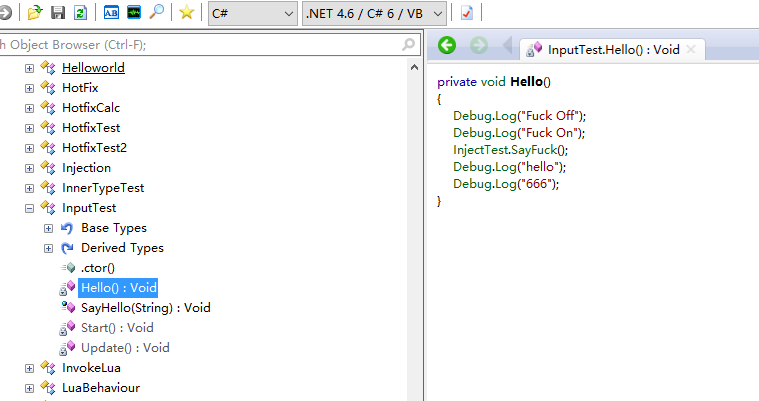
可以看到已经成功的修改啦。